Why is Anthropic’s training data disclosure AI-generated?
Anthropic and its peers don’t seem to be taking California’s data transparency law seriously.
By
Tyler Johnston
-

California’s AB 2013 requires AI companies to disclose information about the data used to train their models. This info includes the sources and owners of the datasets, the number and types of data points, and other data attributes.
I was recently looking through Anthropic’s AB 2013 disclosure and noticed something interesting: it appeared to be entirely AI-generated.
If you’ve ever asked Anthropic’s chatbot, Claude, to make a document for you, you may have noticed a few stylistic quirks. Some of these are the usual chatbot habits of making extensive use of HTML headings and bullet point lists with bolded labels followed by a colon (for more info on these and others, see Wikipedia’s excellent list of such tells). Claude also has some specific quirks. I’ve noticed that when tasked with creating a Word document or a spreadsheet, it often uses a dark blue accent for headings while using an italicized light gray for subtitles and marginalia.

Anthropic’s AB 2013 disclosure
When I first came across Anthropic’s AB 2013 disclosure, I immediately noticed that it had all of these quirks. I had a very strong suspicion that the text was AI-generated. But, of course, stylistic quirks alone don’t prove anything. So I turned to Pangram, an AI detector that, unlike the cottage industry of detectors that preceded it, seems to have achieved the remarkable feat of a near-zero false positive rate. That is to say that when Pangram tells you a document is AI-generated, there’s a very low chance that it’s wrong (they claim a false positive rate of 1 in 10,000, and independent testing seems consistent with a near-zero rate.)
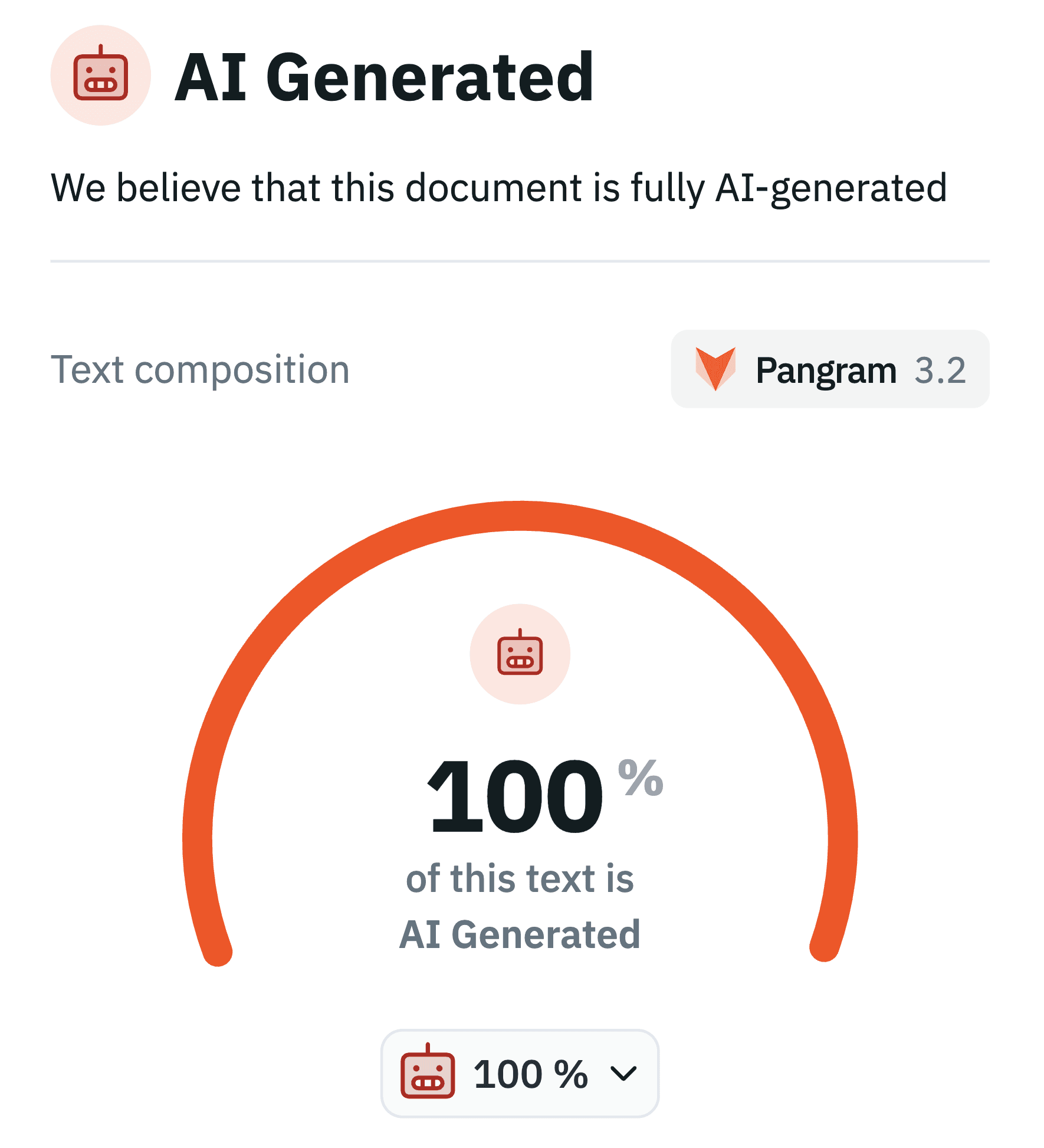
As suspected, Anthropic’s AB 2013 policy is classified by Pangram as 100% AI-generated. The 100% figure is especially interesting because, in my experience, Pangram has achieved its low false-positive rate by accepting a much higher rate of false negatives. In my testing, I’ve found that when AI-generated text is even lightly edited, or just prompted in careful and specific ways, such as providing a lot of specific factual information in the context window, the output doesn’t always trigger the detector (at least not across the entire document). This seems to match experiences others have reported. So, for a document to come back with a label of 100% AI-generated often indicates little to no careful prompting or back-and-forth editing in the creation process. Also, confusingly and perhaps confirming its provenance, the title of the PDF document is “[DRAFT] ACP - AB 2013 Training Data Documentation.” What does ACP mean here? I’m not sure, but I think it might be Agent Communication Protocol.
So, if we buy Pangram’s accuracy claims, we’re looking at an ~99.99% chance that Anthropic’s AB 2013 disclosure was fully generated by AI. Is this a problem?
I tend to think that present-day AI adoption is largely a good thing, and surely Anthropic would be the first to tell you that you can use Claude to automate tedious tasks at work. So, charitably, you could see this as them putting their money where their mouth is and using Claude to write their legally-mandated transparency disclosures, freeing up their lawyers’ time for more important things (like handling the $1.5 billion settlement they face related to claims about their training data).
But, less charitably, you could also see this as Anthropic phoning it in. Most regular AI users will admit that when it comes to complicated, technical tasks, raw AI outputs are often just not that good, misunderstanding both the purpose of the task and the facts underlying it in subtle ways. Therefore, it often requires careful prompting, subsequent editing, and many back-and-forth revisions to turn AI-generated text into something accurate and usable.
The truth, as with many things, is that AI automation of knowledge work won’t have these problems forever — surely at some point AI will outperform humans at these very tasks — but today it can be a harbinger of superficial, low-quality, and inaccurate content, otherwise known as “slop.”
So the more interesting question we can ask about Anthropic’s AI-generated training data disclosure is not “was it AI-generated?” but rather “is it slop?”. To be specific, I think there are three questions that we should ask about the policy, and we should treat each with a higher degree of scrutiny given the nature of its provenance:
Does it meet the spirit of the law?
I think the answer is an obvious no.
I myself am something of a fair-use apologist, having long distrusted restrictive intellectual property laws and overall found myself somewhat sympathetic to the AI industry’s argument that model training is inherently transformative. I also am not a big fan of the text of AB 2013 as written, thinking it demands specificity in some unimportant areas (like the date that datasets began use in training) while ignoring it in others (like the presence of dangerous material in datasets including CSAM, information about biological weapons, and information related to benchmarks used for the evaluation of AI models, as well as the specific steps taken to filter this data).
Nonetheless, I think that AI companies need to operate with democratic legitimacy; when laws are passed, they should make every effort to follow these laws to the best of their ability, including addressing the spirit of the law rather than just doing box-checking or exploiting loopholes. It’s obvious that the spirit of AB 2013, passed near-unanimously by both houses in California, was to give the public a deeper understanding of the nature of the training datasets used by Anthropic and other frontier AI developers. It may have even been intended to give the companies themselves a better sense of their own training data, creating a paper trail through the internal discovery of these facts that could lead to the company changing their practices (or, if they refuse to, one day being held accountable for genuinely negligent, malicious, or deceptive practices relating to training data).
The policy Anthropic released has not given me a better understanding of the nature of their training datasets, and I doubt writing the policy gave them a better sense of the data they use. It seems like it was written to be maximally vague, gesturing at facts about the process that were already widely known as industry standard (e.g. that they have web scrapers doing some unspecified amount of web scraping, or that they purchase datasets from third parties) without actually engaging with the interesting and sometimes-thorny questions of how they design that process, the overall composition of the data that informs the model’s behavior, what steps they take to create guardrails and filter data and ensure appropriate usage of the information they have access to, etc.
For example, one of the key requirements of AB 2013 was the disclosure of the “sources or owners of the datasets,” as well as “the types of data points within the datasets.” It’s obvious to see how this sort of disclosure is in the public interest. For example, it would be good to know: were the models trained on all the videos on YouTube? Were the models trained on pornographic videos? Were the models trained on information about virology or biothreat research? Were the models trained on Anna’s Archive? Were they trained on your emails?
Anthropic’s answer to this is “Well, we train on the internet, and data people sell us.” That’s genuinely about all the detail they offer. The full text from their policy is below:

From Anthropic’s AB 2013 disclosure
It’s pretty clear to me that this doesn’t meet the spirit of the statute. It is true that data sources are proprietary, and there are reasons related to competitive advantage for companies like Anthropic to want to be less-than-forthcoming about the exact sources of the data. It’s perhaps for this reason that the law allows for a “high-level summary” of such information, and indeed Anthropic might feel like they have on paper met this statutory requirement with their answer (“we train on the internet and other data” is indeed a high-level summary). Even so, they clearly have not met the spirit of the law by providing any new, specific information about the nature of the data, its provenance, and the steps they take to process it.
Does it meet the statutory requirements of the law?
If Anthropic were indeed doing legal box-checking, allowing them to technically comply with AB 2013 even without meeting the spirit of the law, they’d retain a great deal of credibility in my mind. Yes, they wouldn’t be doing the public any favors with their disclosure, but they wouldn’t be standing in defiance of regulators either — they would have, even by way of technicalities, done the specific things asked of them. In other words, they’d be playing by the rules of the game, even if they refuse to go one single step further.
But I don’t think Anthropic’s policy meets the minimum statutory requirements of AB 2013. For example, in addition to disclosing the sources of datasets, AB 2013 requires that companies disclose “the number of data points included in the datasets, which may be in general ranges.” In response to this, Anthropic writes: “Claude models are trained on large-scale datasets comprising billions of tokens of text data, images, and multimedia content.”
Does this give the reader an accurate picture of the number of data points included in Anthropic’s training datasets? I don’t think so. Even if you interpret the statutory requirement as something as simple as “estimate the order of magnitude of the sum number of tokens across all datasets in the training corpus as a whole,” then the number “billions” is clearly an underestimate by, I would say, 4-6 orders of magnitude (for example, Meta’s 2024 model Llama 3 was pretrained on a 15 trillion token dataset).
Another requirement of the statute is the disclosure of “the time period during which the data in the datasets were collected.” What does Anthropic say about this? They write: “For current Claude models, the time period for collection of publicly available information varies by model version and can be found in the relevant model’s model or system card. Data collection from third-party sources, data labeling services, opted-in user contributions, and internal generation occurs on an ongoing basis throughout model development cycles.”
This basically means nothing, but they do gesture at the model card for more specifics. But it turns out the system card for Claude Opus 4.7, their most recently publicly released model, doesn’t contain the time period for data collection as they claim:

From Anthropic’s Opus 4.7 model card
The statute also requires disclosure of “the dates the datasets were first used during the development of the artificial intelligence system,” but no such dates appear either in the AB 2013 disclosure statement or in the model card for their most recent model, Claude Opus 4.7.
Another requirement of the statute is the disclosure of whether “the datasets include aggregate consumer information.” Anthropic’s answer to this is “Training datasets may include aggregate consumer information to the extent such information is present in publicly available internet content or acquired datasets.” But this is, of course, a trivially true claim; even before the disclosure was released, anyone could have told you that training data may include said information if it’s present in the dataset. The law isn’t asking for that sort of conditional reasoning; it’s asking for a specific answer on whether the data is present, and the course of action for a company like Anthropic should have been to investigate the training data, answer that question, and disclose the answer.
There are various other issues throughout the disclosure, which I won’t get into because they quickly devolve into litigating the boundaries of how vague a sentence can be before it no longer materially conveys the information needed to comply with the text of a statute. I’ll leave this question for courts and regulators to answer.
Does it accurately reflect Anthropic’s practices?
Looking at all of the above, I lean toward the conclusion that the policy is, indeed, total slop. It’s not clear to me whether there were any careful prompting, editing, or revision processes to ensure that the disclosure actually met the requirements to which Anthropic is subject, nor the broader spirit of the law. It’s not even clear to me if there was any relationship between some minimal internal investigation of Anthropic’s data practices and the policy text generated by the AI. I’ve experimented with asking Claude to write a policy for a hypothetical AI lab given the text of the statute, assuming industry standard training practices while being maximally vague so as to preserve competitive advantage, and it writes up various policies that resemble this one, even with near-identical phrases matching the disclosure Anthropic published.
It’s hard to adjudicate this as an outsider to the company, and I might be wrong, but I don’t think the disclosure provides the reader with an accurate picture of Anthropic’s internal practices. To take one example: in 2024, Anthropic hired Tom Turvey and tasked him with obtaining “all the books in the world” for the purpose of destructive book scanning. AB 2013 is meant to cover training for all models released since 2022, so presumably, the data Anthropic secured from its destructive book scanning process is the sort of data that is meant to be disclosed in this policy. But recall that their policy basically only points to data from web scraping and data from commercial arrangements with third parties. Unless they spun up a new company to do destructive book scanning, contracted with that company, and can thus classify it as data “obtained from third-party providers through commercial arrangements,” they’ve left out at least one major source of data.
Similarly, Anthropic lists four types of data points in its disclosure: text data, image data, human preference data, and safety and adversarial data. But Claude also offers a voice mode where you can talk back-and-forth with the model. Unless this mode operates strictly on text-to-speech features plugged into the app and created outside the company, one would think Claude has also been trained on audio data in one way or another (as is standard practice among its competitors).

From Anthropic’s AB 2013 disclosure
With regard to intellectual property, the policy does mention that “consistent with standard industry practice of training LLMs,” the training data “may include material covered by third-party intellectual property rights.” But this is an understatement. The training data does include this material, and a lot of it. Anthropic’s disclosure makes no specific mention of the pirated training data that has since been exposed in litigation, including the use of Books3, PiLiMi, and Libgen to download pirated books. Despite the fact that they agreed to destroy these datasets, AB 2013 covers models released since 2022, so such disclosures should be present in a document like this. Obviously, Anthropic could argue that they have adequately provided a “high-level summary,” acknowledging that, consistent with standard industry practice, they “may have” pirated millions of books, but my takeaway is that any reasonable reader would come away from this understated summary with an incomplete understanding of the company’s past relationship to protected intellectual property.
Despite all of this, I hate to say that Anthropic is in good company. In fact, its disclosure may be the best among its peers. Other companies like xAI and OpenAI have released disclosures that, while seemingly human-authored, are similarly vague and present a number of the same problems discussed here. Among all of them, Anthropic’s is the longest and, on many metrics, the most detailed.

OpenAI’s AB 2013 Disclosure

xAI’s AB 2013 Disclosure
The truth is that AI companies currently do not have the sort of democratic legitimacy that stems from making an earnest attempt to encourage and abide by the rules imposed upon them by the democratic process.
They have, at times, asked for more regulation to address the risks of the upcoming intelligence explosion. I believe their concern about this is sincere. But the few laws that have been passed so far are maximally light-touch, and despite this, companies like Anthropic have responded with weak-and-vague gestures which resemble compliance while undercutting the spirit of, and in some cases the material requirements of, those very laws. None of this bodes well for their ability to be a productive participant in the complicated and high-stakes regulatory regime that might emerge around superintelligence.
Companies like xAI and OpenAI have gone beyond mere noncompliance. The former is currently suing to block the enforcement of AB 2013, arguing that it represents a form of compelled speech and as such violates the First Amendment. OpenAI’s affiliates are currently behind a $140 million super PAC to punish state lawmakers who have passed some of these light-touch regulations and, in doing so, discourage further lawmaking that opposes the industry’s interests.
It’s no surprise to me, then, that the broader public is largely reacting to these companies and their products with a sense of distrust. As their own lobbyists sometimes admit, the AI industry has failed to tell a story of how their technologies will create a world that people actually want to live in, and when the people have begun to implement the rules that they think would be fair for this emerging industry, the companies have responded with lawsuits, political spending, and malicious compliance in the form of AI slop.
I hope Anthropic one day decides to sit down and actually write out an informative description of their current relationship to the acquisition and use of training data, as they’ve done for model behavior, model capabilities, and even model welfare. They may personally want to write off concerns around training data, especially in light of the emergence of civilization-changing technology like recursive self-improvement, which they think is only years away. But the first step to developing a productive relationship with regulators and the public is to take their concerns seriously and make an earnest attempt to abide by the rules the democratic process has set.
California’s AB 2013 requires AI companies to disclose information about the data used to train their models. This info includes the sources and owners of the datasets, the number and types of data points, and other data attributes.
I was recently looking through Anthropic’s AB 2013 disclosure and noticed something interesting: it appeared to be entirely AI-generated.
If you’ve ever asked Anthropic’s chatbot, Claude, to make a document for you, you may have noticed a few stylistic quirks. Some of these are the usual chatbot habits of making extensive use of HTML headings and bullet point lists with bolded labels followed by a colon (for more info on these and others, see Wikipedia’s excellent list of such tells). Claude also has some specific quirks. I’ve noticed that when tasked with creating a Word document or a spreadsheet, it often uses a dark blue accent for headings while using an italicized light gray for subtitles and marginalia.
Anthropic’s AB 2013 disclosure
When I first came across Anthropic’s AB 2013 disclosure, I immediately noticed that it had all of these quirks. I had a very strong suspicion that the text was AI-generated. But, of course, stylistic quirks alone don’t prove anything. So I turned to Pangram, an AI detector that, unlike the cottage industry of detectors that preceded it, seems to have achieved the remarkable feat of a near-zero false positive rate. That is to say that when Pangram tells you a document is AI-generated, there’s a very low chance that it’s wrong (they claim a false positive rate of 1 in 10,000, and independent testing seems consistent with a near-zero rate.)
As suspected, Anthropic’s AB 2013 policy is classified by Pangram as 100% AI-generated. The 100% figure is especially interesting because, in my experience, Pangram has achieved its low false-positive rate by accepting a much higher rate of false negatives. In my testing, I’ve found that when AI-generated text is even lightly edited, or just prompted in careful and specific ways, such as providing a lot of specific factual information in the context window, the output doesn’t always trigger the detector (at least not across the entire document). This seems to match experiences others have reported. So, for a document to come back with a label of 100% AI-generated often indicates little to no careful prompting or back-and-forth editing in the creation process. Also, confusingly and perhaps confirming its provenance, the title of the PDF document is “[DRAFT] ACP - AB 2013 Training Data Documentation.” What does ACP mean here? I’m not sure, but I think it might be Agent Communication Protocol.
So, if we buy Pangram’s accuracy claims, we’re looking at an ~99.99% chance that Anthropic’s AB 2013 disclosure was fully generated by AI. Is this a problem?
I tend to think that present-day AI adoption is largely a good thing, and surely Anthropic would be the first to tell you that you can use Claude to automate tedious tasks at work. So, charitably, you could see this as them putting their money where their mouth is and using Claude to write their legally-mandated transparency disclosures, freeing up their lawyers’ time for more important things (like handling the $1.5 billion settlement they face related to claims about their training data).
But, less charitably, you could also see this as Anthropic phoning it in. Most regular AI users will admit that when it comes to complicated, technical tasks, raw AI outputs are often just not that good, misunderstanding both the purpose of the task and the facts underlying it in subtle ways. Therefore, it often requires careful prompting, subsequent editing, and many back-and-forth revisions to turn AI-generated text into something accurate and usable.
The truth, as with many things, is that AI automation of knowledge work won’t have these problems forever — surely at some point AI will outperform humans at these very tasks — but today it can be a harbinger of superficial, low-quality, and inaccurate content, otherwise known as “slop.”
So the more interesting question we can ask about Anthropic’s AI-generated training data disclosure is not “was it AI-generated?” but rather “is it slop?”. To be specific, I think there are three questions that we should ask about the policy, and we should treat each with a higher degree of scrutiny given the nature of its provenance:
Does it meet the spirit of the law?
I think the answer is an obvious no.
I myself am something of a fair-use apologist, having long distrusted restrictive intellectual property laws and overall found myself somewhat sympathetic to the AI industry’s argument that model training is inherently transformative. I also am not a big fan of the text of AB 2013 as written, thinking it demands specificity in some unimportant areas (like the date that datasets began use in training) while ignoring it in others (like the presence of dangerous material in datasets including CSAM, information about biological weapons, and information related to benchmarks used for the evaluation of AI models, as well as the specific steps taken to filter this data).
Nonetheless, I think that AI companies need to operate with democratic legitimacy; when laws are passed, they should make every effort to follow these laws to the best of their ability, including addressing the spirit of the law rather than just doing box-checking or exploiting loopholes. It’s obvious that the spirit of AB 2013, passed near-unanimously by both houses in California, was to give the public a deeper understanding of the nature of the training datasets used by Anthropic and other frontier AI developers. It may have even been intended to give the companies themselves a better sense of their own training data, creating a paper trail through the internal discovery of these facts that could lead to the company changing their practices (or, if they refuse to, one day being held accountable for genuinely negligent, malicious, or deceptive practices relating to training data).
The policy Anthropic released has not given me a better understanding of the nature of their training datasets, and I doubt writing the policy gave them a better sense of the data they use. It seems like it was written to be maximally vague, gesturing at facts about the process that were already widely known as industry standard (e.g. that they have web scrapers doing some unspecified amount of web scraping, or that they purchase datasets from third parties) without actually engaging with the interesting and sometimes-thorny questions of how they design that process, the overall composition of the data that informs the model’s behavior, what steps they take to create guardrails and filter data and ensure appropriate usage of the information they have access to, etc.
For example, one of the key requirements of AB 2013 was the disclosure of the “sources or owners of the datasets,” as well as “the types of data points within the datasets.” It’s obvious to see how this sort of disclosure is in the public interest. For example, it would be good to know: were the models trained on all the videos on YouTube? Were the models trained on pornographic videos? Were the models trained on information about virology or biothreat research? Were the models trained on Anna’s Archive? Were they trained on your emails?
Anthropic’s answer to this is “Well, we train on the internet, and data people sell us.” That’s genuinely about all the detail they offer. The full text from their policy is below:
From Anthropic’s AB 2013 disclosure
It’s pretty clear to me that this doesn’t meet the spirit of the statute. It is true that data sources are proprietary, and there are reasons related to competitive advantage for companies like Anthropic to want to be less-than-forthcoming about the exact sources of the data. It’s perhaps for this reason that the law allows for a “high-level summary” of such information, and indeed Anthropic might feel like they have on paper met this statutory requirement with their answer (“we train on the internet and other data” is indeed a high-level summary). Even so, they clearly have not met the spirit of the law by providing any new, specific information about the nature of the data, its provenance, and the steps they take to process it.
Does it meet the statutory requirements of the law?
If Anthropic were indeed doing legal box-checking, allowing them to technically comply with AB 2013 even without meeting the spirit of the law, they’d retain a great deal of credibility in my mind. Yes, they wouldn’t be doing the public any favors with their disclosure, but they wouldn’t be standing in defiance of regulators either — they would have, even by way of technicalities, done the specific things asked of them. In other words, they’d be playing by the rules of the game, even if they refuse to go one single step further.
But I don’t think Anthropic’s policy meets the minimum statutory requirements of AB 2013. For example, in addition to disclosing the sources of datasets, AB 2013 requires that companies disclose “the number of data points included in the datasets, which may be in general ranges.” In response to this, Anthropic writes: “Claude models are trained on large-scale datasets comprising billions of tokens of text data, images, and multimedia content.”
Does this give the reader an accurate picture of the number of data points included in Anthropic’s training datasets? I don’t think so. Even if you interpret the statutory requirement as something as simple as “estimate the order of magnitude of the sum number of tokens across all datasets in the training corpus as a whole,” then the number “billions” is clearly an underestimate by, I would say, 4-6 orders of magnitude (for example, Meta’s 2024 model Llama 3 was pretrained on a 15 trillion token dataset).
Another requirement of the statute is the disclosure of “the time period during which the data in the datasets were collected.” What does Anthropic say about this? They write: “For current Claude models, the time period for collection of publicly available information varies by model version and can be found in the relevant model’s model or system card. Data collection from third-party sources, data labeling services, opted-in user contributions, and internal generation occurs on an ongoing basis throughout model development cycles.”
This basically means nothing, but they do gesture at the model card for more specifics. But it turns out the system card for Claude Opus 4.7, their most recently publicly released model, doesn’t contain the time period for data collection as they claim:
From Anthropic’s Opus 4.7 model card
The statute also requires disclosure of “the dates the datasets were first used during the development of the artificial intelligence system,” but no such dates appear either in the AB 2013 disclosure statement or in the model card for their most recent model, Claude Opus 4.7.
Another requirement of the statute is the disclosure of whether “the datasets include aggregate consumer information.” Anthropic’s answer to this is “Training datasets may include aggregate consumer information to the extent such information is present in publicly available internet content or acquired datasets.” But this is, of course, a trivially true claim; even before the disclosure was released, anyone could have told you that training data may include said information if it’s present in the dataset. The law isn’t asking for that sort of conditional reasoning; it’s asking for a specific answer on whether the data is present, and the course of action for a company like Anthropic should have been to investigate the training data, answer that question, and disclose the answer.
There are various other issues throughout the disclosure, which I won’t get into because they quickly devolve into litigating the boundaries of how vague a sentence can be before it no longer materially conveys the information needed to comply with the text of a statute. I’ll leave this question for courts and regulators to answer.
Does it accurately reflect Anthropic’s practices?
Looking at all of the above, I lean toward the conclusion that the policy is, indeed, total slop. It’s not clear to me whether there were any careful prompting, editing, or revision processes to ensure that the disclosure actually met the requirements to which Anthropic is subject, nor the broader spirit of the law. It’s not even clear to me if there was any relationship between some minimal internal investigation of Anthropic’s data practices and the policy text generated by the AI. I’ve experimented with asking Claude to write a policy for a hypothetical AI lab given the text of the statute, assuming industry standard training practices while being maximally vague so as to preserve competitive advantage, and it writes up various policies that resemble this one, even with near-identical phrases matching the disclosure Anthropic published.
It’s hard to adjudicate this as an outsider to the company, and I might be wrong, but I don’t think the disclosure provides the reader with an accurate picture of Anthropic’s internal practices. To take one example: in 2024, Anthropic hired Tom Turvey and tasked him with obtaining “all the books in the world” for the purpose of destructive book scanning. AB 2013 is meant to cover training for all models released since 2022, so presumably, the data Anthropic secured from its destructive book scanning process is the sort of data that is meant to be disclosed in this policy. But recall that their policy basically only points to data from web scraping and data from commercial arrangements with third parties. Unless they spun up a new company to do destructive book scanning, contracted with that company, and can thus classify it as data “obtained from third-party providers through commercial arrangements,” they’ve left out at least one major source of data.
Similarly, Anthropic lists four types of data points in its disclosure: text data, image data, human preference data, and safety and adversarial data. But Claude also offers a voice mode where you can talk back-and-forth with the model. Unless this mode operates strictly on text-to-speech features plugged into the app and created outside the company, one would think Claude has also been trained on audio data in one way or another (as is standard practice among its competitors).
From Anthropic’s AB 2013 disclosure
With regard to intellectual property, the policy does mention that “consistent with standard industry practice of training LLMs,” the training data “may include material covered by third-party intellectual property rights.” But this is an understatement. The training data does include this material, and a lot of it. Anthropic’s disclosure makes no specific mention of the pirated training data that has since been exposed in litigation, including the use of Books3, PiLiMi, and Libgen to download pirated books. Despite the fact that they agreed to destroy these datasets, AB 2013 covers models released since 2022, so such disclosures should be present in a document like this. Obviously, Anthropic could argue that they have adequately provided a “high-level summary,” acknowledging that, consistent with standard industry practice, they “may have” pirated millions of books, but my takeaway is that any reasonable reader would come away from this understated summary with an incomplete understanding of the company’s past relationship to protected intellectual property.
Despite all of this, I hate to say that Anthropic is in good company. In fact, its disclosure may be the best among its peers. Other companies like xAI and OpenAI have released disclosures that, while seemingly human-authored, are similarly vague and present a number of the same problems discussed here. Among all of them, Anthropic’s is the longest and, on many metrics, the most detailed.
OpenAI’s AB 2013 Disclosure
xAI’s AB 2013 Disclosure
The truth is that AI companies currently do not have the sort of democratic legitimacy that stems from making an earnest attempt to encourage and abide by the rules imposed upon them by the democratic process.
They have, at times, asked for more regulation to address the risks of the upcoming intelligence explosion. I believe their concern about this is sincere. But the few laws that have been passed so far are maximally light-touch, and despite this, companies like Anthropic have responded with weak-and-vague gestures which resemble compliance while undercutting the spirit of, and in some cases the material requirements of, those very laws. None of this bodes well for their ability to be a productive participant in the complicated and high-stakes regulatory regime that might emerge around superintelligence.
Companies like xAI and OpenAI have gone beyond mere noncompliance. The former is currently suing to block the enforcement of AB 2013, arguing that it represents a form of compelled speech and as such violates the First Amendment. OpenAI’s affiliates are currently behind a $140 million super PAC to punish state lawmakers who have passed some of these light-touch regulations and, in doing so, discourage further lawmaking that opposes the industry’s interests.
It’s no surprise to me, then, that the broader public is largely reacting to these companies and their products with a sense of distrust. As their own lobbyists sometimes admit, the AI industry has failed to tell a story of how their technologies will create a world that people actually want to live in, and when the people have begun to implement the rules that they think would be fair for this emerging industry, the companies have responded with lawsuits, political spending, and malicious compliance in the form of AI slop.
I hope Anthropic one day decides to sit down and actually write out an informative description of their current relationship to the acquisition and use of training data, as they’ve done for model behavior, model capabilities, and even model welfare. They may personally want to write off concerns around training data, especially in light of the emergence of civilization-changing technology like recursive self-improvement, which they think is only years away. But the first step to developing a productive relationship with regulators and the public is to take their concerns seriously and make an earnest attempt to abide by the rules the democratic process has set.
More From Model Republic
More From Model Republic
Further investigations into AI power, policy, and accountability.
Further investigations into AI power, policy, and accountability.



Power & Policy
Deeply researched analysis of the AI industry, policy moves, and the forces shaping the rules of artificial intelligence — delivered to your email.
Power & Policy
Deeply researched analysis of the AI industry, policy moves, and the forces shaping the rules of artificial intelligence — delivered to your email.
Power & Policy
Deeply researched analysis of the AI industry, policy moves, and the forces shaping the rules of artificial intelligence — delivered to your email.
This will hide itself!